How to Build an Auditable University Data Warehouse with Medallion Architecture
- Published on: November 11, 2025
- Updated on: July 7, 2026
- Reading Time: 12 mins
-
Views
Data Modeling with Data Vault 2.0 & Dimensional Modeling
Data Warehouse Blueprint: A Modern Architectural Approach
But First, Why Not Just Build a Star Schema Directly?
The Three Core Layers Of Medallion Architecture
Step 1: The Bronze Layer – The Raw Foundation
Step 2: The Silver Layer – Forging the Enterprise Vault
Part A: The Raw Vault – An Auditable Foundation
Raw Vault – ER Diagram
The Magic of Historization (SCD Type 2)
Part B: The Business Vault – Applying Logic with Agility
Step 3: The Gold Layer – Polished Data Mart for Analytics
Building the Academic Performance Data Mart
Building the Financial Operations Data Mart
Step 4: The Payoff – Powerful, Cross-Functional Analytics
Verification
FAQs
Data Modeling with Data Vault 2.0 & Dimensional Modeling
Universities manage a vast and complex web of information. Student enrollments, faculty assignments, and organizational structures change every semester. How do you build a data warehouse that not only handles this complexity but also provides a complete, auditable history of every change? The answer lies in combining two powerful methodologies: the Medallion Architecture for structuring our data platform and Data Vault 2.0 for modeling it with unparalleled flexibility and auditability.
This blog is a hands-on, end-to-end walkthrough using a real-world university scenario with OneRoster-compliant data. We will build a complete, working system in PostgreSQL, moving data from its raw state to analytics-ready Data Marts, and you can follow along with the provided code.
Data Warehouse Blueprint: A Modern Architectural Approach
At a high level, the Medallion Architecture provides a simple, powerful way to organize data logically. It separates the raw, messy data from the clean, business-ready data, ensuring quality and reliability.
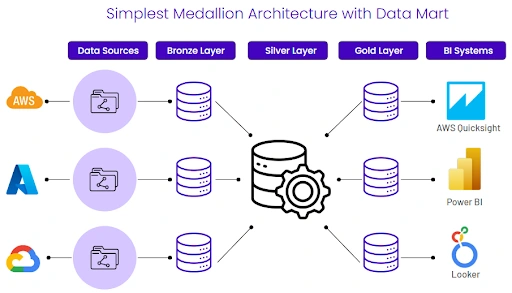
In simple terms, this image shows the flow of data from various sources (like AWS, Azure, Google Cloud) on the left, moving through organized layers (Bronze, Silver, Gold), and finally being served to Business Intelligence systems (like Quicksight, Power BI, Looker, Tableau) on the right. The Silver Layer acts as the central, integrated hub, while the Gold Layer provides specialized, high-performance views for different business needs.
For our university data warehouse, we will implement this pattern using a detailed, process-oriented approach that incorporates Data Vault 2.0 for maximum auditability and flexibility.
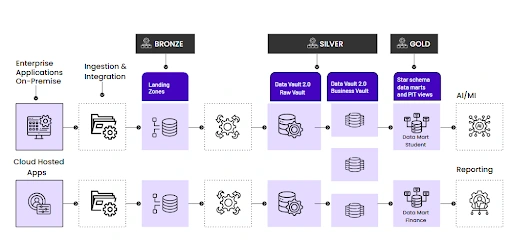
This diagram is our roadmap for the rest of this article. It shows data flowing from enterprise applications into Bronze landing zones. From there, it’s modeled into the Silver Layer, which is split into a Raw Vault (for pure, audited integration) and a Business Vault (for applying business rules). Finally, the integrated data is transformed into specialized, subject-oriented Gold Layer Data Marts (like Student and Finance), which are optimized for high-speed Reporting and AI/ML applications.
Now that we have our roadmap, let’s start building, layer by layer.
But First, Why Not Just Build a Star Schema Directly?
Before we dive in, a common question arises: “Why not just take the raw data from the Bronze Layer and build our analytical Star Schema directly in the Gold Layer?” It seems simpler, but this approach hides critical long-term problems:
- Poor Auditability: When you transform data directly from source to report, you lose the original context. If a report looks wrong, tracing the data’s journey and proving its correctness is nearly impossible. You can’t answer “What did this record look like six months ago?”
- Brittle Transformation Logic: Business rules get hardcoded into a single, massive ETL/ELT script. When a business rule changes, you have to perform complex and risky surgery on this code, often leading to breaks and requiring a full reload of the data.
- Difficulty Integrating New Sources: What happens when the university adds a new student information system? Trying to merge a new source directly into an existing Star Schema is incredibly difficult and often requires redesigning the entire model.
The Silver Layer, modeled with Data Vault, solves these problems by creating a stable, integrated, and fully auditable foundation before you even think about analytics.
Understanding the Three Core Layers Of Medallion Architecture
Our entire process will follow the Medallion Architecture, which organizes data into three distinct layers:
- Bronze Layer: The raw, unfiltered source data. Untouched and immutable, it’s our historical archive.
- Silver Layer: The validated, conformed, and modeled data. This is where we will build our Data Vault, creating an enterprise-wide view of our core business entities and relationships.
- Gold Layer: The curated, aggregated data optimized for business intelligence (BI) and analytics. This is where we’ll build our user-friendly Star Schema.
Step 1: The Bronze Layer – The Raw Foundation
Our journey starts with the source system. For our university, we’ll use a data model compliant with OneRoster, a common standard for academic data. We create a bronze_oneroster schema to land our raw data.
The core tables are:
- Users: Students, faculty, and staff.
- Orgs: The university, its colleges, and departments.
- Enrollments: The link that shows which users belong to which orgs and in what capacity.

Crucially, our data includes a fictional faculty member named Jane Smith. We’ll use Jane to demonstrate one of Data Vault’s most powerful features: handling changes over time.
Step 2: The Silver Layer – Forging the Enterprise Vault
This is the heart of our architecture. Here, we transform our raw Bronze data into a structured, auditable, and historically preserved Data Vault. Our Silver Layer is split into two key parts: the Raw Vault and the Business Vault.
Part A: The Raw Vault – An Auditable Foundation
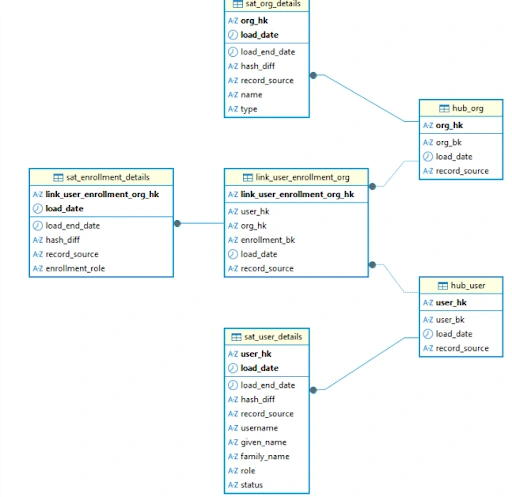
The Raw Vault integrates data from our source systems without applying any business logic. It’s built on three core components:
- Hubs: Represent core business entities. They contain only the unique business key (like userSourcedId). Think of them as the “nouns” of the business. We create hub_user and hub_org.
- Links: Represent the relationships between Hubs. Our link_user_enrollment_org will capture the many-to-many relationships between users and organizations.
- Satellites: Contain all the descriptive attributes (the context) about Hubs and Links. They store data that changes over time, like a user’s name or an org’s type.
A key principle of Data Vault 2.0 is using hashed keys. We generate an MD5 hash of the business key for every Hub, Link, and Satellite. This allows for massive parallel loading, as the key is deterministic and can be calculated anywhere without needing a central sequence generator.
Raw Vault – ER Diagram
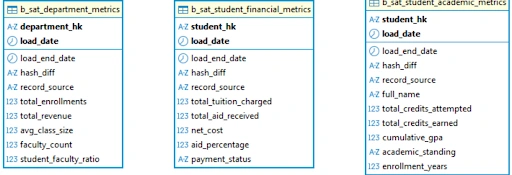
Business Vault – ER Diagram
As shown in the diagrams, the Raw Vault provides the core, integrated structure, while the Business Vault attaches calculated metrics directly to these core entities, which we will build next.

The Magic of Historization (SCD Type 2)
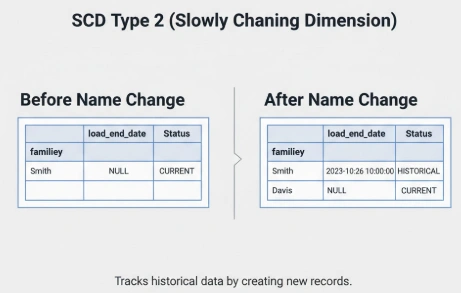
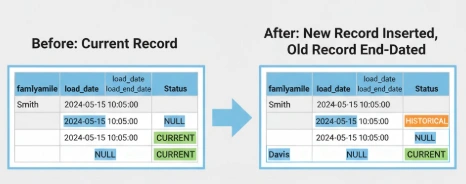
Now, let’s simulate a real-world change. Jane Smith gets married, and her name changes to Jane Davis. In a traditional data model, you might just overwrite the old record, losing history forever. In Data Vault, we preserve it.
1. The source data is updated:

2. We process this change in our sat_user_details table:
First, we “end-date” the old record. We find the current record for Jane (load_end_date IS

Next, we insert a new satellite record with the updated familyName (‘Davis’). This new record has a new load_date and a load_end_date of NULL, marking it as the current version.

We now have a complete, auditable history of this user’s name change, tracked to the microsecond.
Part B: The Business Vault – Applying Logic with Agility
The Raw Vault is pure. The Business Vault is where we apply business rules and create derived, business-centric information. This separation is key to agility.
Why is this separation so important? Imagine the university decides to change how it defines a full_name (e.g., to ‘LastName, FirstName’ or to include a middle initial). With this architecture, we only need to update the Business Vault logic. The Raw Vault, our stable, auditable foundation of source data, remains untouched. This prevents costly and complex rework of the core integration layer and allows us to adapt to business changes rapidly.
Let’s create a full_name for each user. We build a business satellite that attaches to hub_user and stores this derived data.

This keeps our Raw Vault pristine while allowing us to build valuable business assets on top of it.
Step 3: The Gold Layer – Polished Data Mart for Analytics
While our Silver Vault is a fantastic integration layer, its normalized structure (requiring many joins) is not ideal for end-user queries. The Gold Layer solves this. Here, we build denormalized, subject-oriented Data Marts using a Star Schema, the lingua franca of BI tools like Tableau and Power BI.
A Data Mart is a subset of the data warehouse that is focused on a specific business line or team (e.g., Academics, Finance, Admissions). This focus makes them easier for end-users to understand and provides much faster query performance.
Following our roadmap, we will build two distinct data marts.
Building the Academic Performance Data Mart
This mart is designed for the Registrar’s office or Academic Affairs to analyze student performance, course popularity, and program effectiveness.

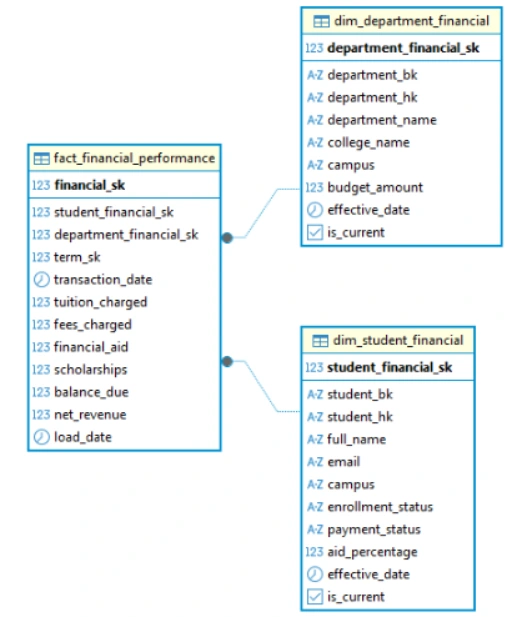
Building the Financial Operations Data Mart
This mart is designed for the Bursar’s office or the Finance department to analyze tuition revenue, financial aid distribution, and departmental budgets. Notice how `dim_student_financial` might have different attributes than the academic `dim_student`.

Step 4: The Payoff – Powerful, Cross-Functional Analytics
With our specialized Gold marts in place, answering complex business questions becomes simple, fast, and intuitive.
Academic Mart Query: “Which courses have the highest number of enrollments in the ‘College of Engineering’?”

Cross-Mart Query (The True Power): “What is the average final grade for students who receive more than $5,000 in financial aid?”
This powerful question requires joining information across our two data marts. This is possible because our dimensions (like the student dimension) are conformed—they share common keys (user_bk) and consistent meanings.

This is something that would be incredibly difficult and slow to query directly from the Silver Layer, but is made simple by our well-designed Gold marts.
Verification
“Show me the complete name history of user ‘user_002’.”
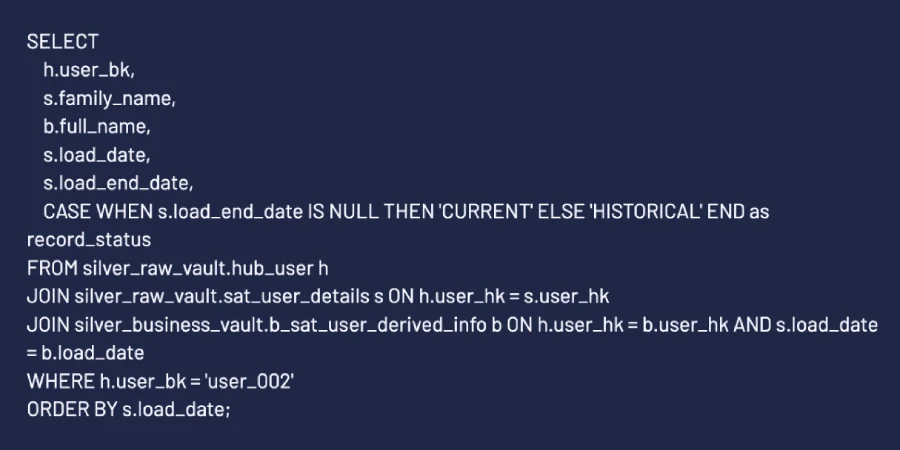
Result:

The proof is in the data. We have a perfect audit trail.
We have successfully journeyed from raw, source-aligned data in the Bronze Layer to a fully historized, auditable, and integrated Data Vault in the Silver Layer, and finally to a performance-optimized Star Schema in the Gold Layer, ready for any analytical challenge.
This Medallion + Data Vault 2.0 approach provides the best of all worlds:
- Scalability: Handles massive data volumes with parallel loading.
- Auditability: Never loses a single change from the source.
- Flexibility: Easily accommodates new data sources and changing business rules without breaking the core model.
- Clarity: A clear separation of concerns between data integration, business logic, and analytics.
By adopting this architecture, an enterprise like a university can build a data foundation that is not just a repository of information, but a reliable, historical, and agile asset ready for the future.
To know about our data services for universities, visit the Magic EdTech website.

Abhishek Jain is a future-focused technology leader with a 20-year career architecting solutions for education. He has a proven track record of delivering mission-critical systems, including real-time data replication platforms and AI agents for legacy code modernization. Through his experience with Large Language Models, he builds sophisticated AI tools that automate software development.
FAQs
If you have a single, stable source and light audit needs, a direct Star Schema can work. Choose Data Vault when you expect multiple sources, frequent schema changes, or strict audit/history. You can also start small (Bronze → Gold) and add a Raw/Business Vault as complexity grows.
Capture `load_date`, `load_end_date` (for SCD2), `record_source`, and a `hash_diff` of descriptive fields. Pair that with row-level lineage (source IDs), and keep change scripts/tests in version control so you can reproduce any number.
Use conformed keys, incremental builds, and materialized views. Pre‑aggregate heavy facts, index join keys, and schedule refreshes to align with usage windows so dashboards stay snappy.
Central IAM/MDM should own the “one human, many roles” ID. Map and de‑dupe identities, backfill the ID across SIS/LMS/HR, freeze risky merges during census, and publish the golden feed to every pipeline before cutting over.
In the Raw Vault, add new hubs/links/satellites for that source and keep business rules in the Business Vault. Gold marts consume the conformed layer, so you extend—rather than refactor—the model as sources change.

Get In Touch
Reach out to our team with your question and our representatives will get back to you within 24 working hours.